

Beyond Chatbots: Why 2026 is the Year of Multi-Agent Systems
In the early days of enterprise LLM adoption, it was enough to bolt a chatbot onto a wiki, let it draft emails, or spin up a “copilot” for a narrow task. Those pilots proved something important: language models are useful.
But they also proved something equally important: a single prompt-driven agent is the wrong architecture for complex work.
By 2026, the center of gravity has shifted from monolithic chatbots to multi-agent systems (MAS)—federated teams of specialized “digital workers” that can collaborate, cross-check each other, recover from failure, and operate under governance.
If you’re building AI for real business workflows (engineering, security, operations, support, data), this is the year the conversation moves from prompting to systems architecture.
Summary
- Single-agent chatbots are great for drafts and one-off tasks, but they bottleneck on latency, context constraints, reliability, and security.
- Multi-agent systems break complex objectives into specialized subtasks (UI, database, security, QA, ops) and recombine results through an orchestrator.
- The winning capability in 2026 is AI orchestration: routing, memory, tool access, observability, and governance.
- Production-grade MAS requires handoffs, evaluator guardrails, deterministic baselines for testing, and human-on-the-loop oversight.
Table of contents
- Why single-agent chatbots plateau in production
- The 2026 shift: from prompts to orchestration
- Technical deep dive: the Orchestrator–Worker pattern
- Mechanics of agentic handoffs
- Framework patterns defining AI orchestration
- Conquering non-determinism: debugging multi-agent swarms
- Human-on-the-loop governance: guardrails, escalation, circuit breakers
- Reference architecture: a “silicon workforce” you can ship
- Implementation checklist
- FAQ
Why single-agent chatbots plateau in production
Single-agent systems—one model call that tries to do everything—work fine when the task is simple:
- Summarize a document
- Draft a proposal
- Generate a code snippet
- Answer a narrow question
Enterprise workflows, however, aren’t simple. They’re multi-step, multi-stakeholder, and risk-weighted. That exposes four hard limits.
1) Latency stacks up
A “simple” enterprise request like “Build a secure login page” is rarely one step. It includes UI, accessibility, API design, database schema, authentication, tests, monitoring, and security review.
A single agent that does this sequentially creates compounding latency—and the slowest step becomes the pace setter.
2) Context windows get bloated
The more you ask a single agent to juggle, the more context you must feed it:
- Requirements and constraints
- Existing codebase conventions
- Security policies
- Prior attempts and failures
- Tool outputs (logs, diffs, scans)
Token bloat isn’t just a cost problem. It’s a quality problem: irrelevant details can distract the model and increase error rates.
3) Failure recovery is fragile
When a single agent makes a wrong assumption, it tends to cascade:
- One hallucinated variable → broken build
- Broken build → broken tests
- Broken tests → misleading fixes
- Misleading fixes → bad deploy plan
Even worse: postmortems become fuzzy because the “why” is buried in one long conversational thread.
4) Security teams hate all-powerful agents
A single agent with broad tool access contradicts least privilege. In regulated environments, you need:
- Role separation
- Auditing and traceability
- Approval flows for high-risk actions
- Policy enforcement that isn’t optional
A chatbot that can “just do everything” is an incident waiting to happen.
The 2026 shift: from prompts to orchestration
The transition to multi-agent systems is not a cosmetic change. It’s an architectural evolution that mirrors how real organizations work:
- Specialists focus on narrow domains
- Work is delegated and reviewed
- Decisions are logged
- Riskier actions require approvals
- Failures are isolated and corrected
In practice, engineers become orchestrators.
Instead of asking one model to produce a perfect end-to-end result, you design a system where:
- A manager agent decomposes objectives into subtasks
- Specialized agents execute independently (often in parallel)
- Evaluators validate intermediate outputs
- The orchestrator synthesizes the final deliverable
- Governance routes risky decisions to humans
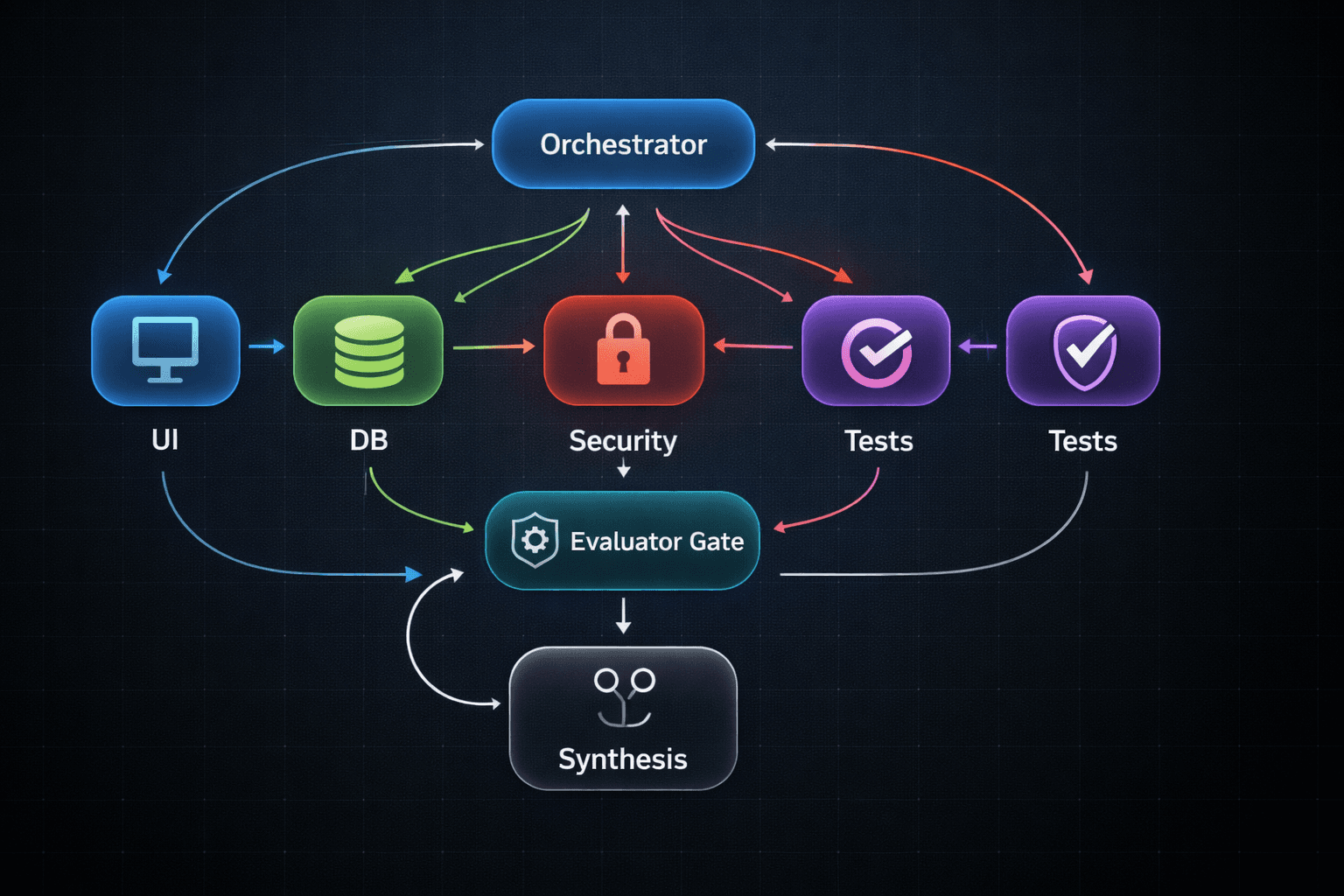
Technical deep dive: the Orchestrator–Worker pattern
At the heart of agentic architecture in 2026 is the Orchestrator–Worker pattern.
What makes it different from a prompt chain?
A prompt chain is typically static:
- Step 1 → Step 2 → Step 3
- Hardcoded branches
- Limited looping or retries
The orchestrator–worker pattern is dynamic at runtime:
- The orchestrator decides how many workers to spawn
- It defines which subtasks exist based on the objective
- It routes feedback and revisions based on evaluator results
This matters most when:
- The number of subtasks is unknown in advance
- The workflow requires cross-domain expertise
- The system must self-correct when something fails
A concrete example: “Build a secure login page”
In a robust MAS, the orchestrator might create these agents:
- UI Designer Agent
- Database Schema Agent
- Security Auditor Agent
- Test Agent
- Ops Agent
Then the orchestrator runs a synthesis loop:
- If the security auditor flags a vulnerability, the orchestrator routes feedback back to the responsible worker.
- If tests fail, the orchestrator triggers a repair loop.
- If risk exceeds policy thresholds, the orchestrator escalates to a human.
Why this pattern scales
Parallelization: Many subtasks are independent, so workers can run simultaneously.
Economic optimization: Use a stronger model for orchestration (planning, synthesis, arbitration), and smaller, faster models for narrow worker tasks.
Reliability through redundancy: Specialized evaluators reduce the chance that one mistake becomes a system-wide failure.
Mechanics of agentic handoffs
A multi-agent system only works if agents can transfer control without losing the plot. That transfer is called a handoff.
The real problem: session amnesia
If a manager agent delegates to a UI agent, the UI agent must inherit:
- the objective
- relevant constraints
- any decisions already made
- the current artifacts (design tokens, components, API shape)
Without that, the UI agent starts from scratch—and you get inconsistency.
Context engineering: pass less, not more
The naive approach is to forward the entire conversation. That often backfires:
- Token cost increases
- Downstream agents inherit irrelevant internal chatter
- The receiving agent gets confused by competing instructions
In production systems, handoffs typically include filtered state:
- a structured summary
- the minimal set of constraints
- the latest artifacts
- open questions
A practical handoff payload
Here’s a simple handoff format that keeps context tight:
{
"objective": "Build a secure login page",
"constraints": [
"Must support MFA",
"Use company design system",
"No PII in logs"
],
"artifacts": {
"api_contract": "POST /auth/login ...",
"db_schema": "users(id, email, password_hash, ... )"
},
"open_questions": [
"SSO provider?",
"Password policy requirements?"
]
}The orchestrator’s job is to keep this state accurate and up-to-date.

Framework patterns defining AI orchestration
By 2026, agentic frameworks tend to cluster into three architectural styles:
- Graph-native orchestration (workflows as directed graphs with loops)
- Event-driven actor models (agents as async message-passing actors)
- Minimalist agent runtimes (few primitives: agents, handoffs, guardrails)
1) Graph-native orchestration
Graph workflows shine when you need:
- explicit state
- retries and cyclic flows
- checkpointing and resumability
- clear visualization of execution paths
In a graph, nodes represent actions (LLM calls, tool runs, validators), and edges define control flow. Cycles are essential for self-correction ("try, evaluate, revise").
2) Event-driven actor models
Actor models emphasize:
- asynchronous message passing
- decoupled components
- modular scaling across teams and services
They fit collaboration patterns like debate, review, or multi-perspective research—especially when “who speaks next” is part of the logic.
3) Minimalist agent runtimes
Minimal runtimes focus on:
- an agent abstraction
- handoffs as first-class control transfers
- guardrails as explicit quality and policy gates
This approach is attractive when you want speed-to-market and don’t want to learn a complex workflow DSL.
A quick comparison table
Conquering non-determinism: debugging multi-agent swarms
Agentic systems are dynamic planners. That means the same input can lead to different execution paths.
The cascading error problem
Agents tend to trust peer messages. One subtle error can propagate:
- An agent invents a config key
- The next agent treats it as truth
- Another agent writes tests against the invented behavior
- The orchestrator synthesizes a broken system confidently
The reliability tax (do the math)
If you have 5 sequential steps and each step is 90% reliable, overall reliability is:
- 0.9 × 0.9 × 0.9 × 0.9 × 0.9
- = 0.9^5
- = 0.59049 (about 59%)
This is why “pretty good” agents still feel flaky at scale.
What actually works in practice
1) Deterministic baselines
For CI/CD, reduce randomness:
- low temperature
- consistent prompts
- fixed test datasets
The goal: reproducible failures.
2) Evaluator guardrails
Introduce evaluator agents (or rule-based validators) that grade intermediate outputs:
- schema compliance
- policy constraints
- factual checks (where possible)
- security minimums
If the output fails validation, the orchestrator routes it back for revision.
3) Observability and replay
Treat agent state as a first-class artifact:
- per-agent logs
- structured state snapshots
- tool traces
- checkpointed runs you can replay
If you can’t inspect and replay execution, you can’t debug it.

Human-on-the-loop governance: guardrails, escalation, circuit breakers
When agents operate at machine speed, approving every micro-action becomes a bottleneck. The practical solution is human-on-the-loop (HOTL):
- Agents operate autonomously inside guardrails
- Humans monitor exceptions
- High-risk actions escalate automatically
Governance-as-code (how it looks)
Instead of “policy docs,” you encode policy into the system.
Here’s a simplified example:
risk_policy:
out_of_loop:
examples:
- "format code"
- "summarize internal document"
controls:
- "post_hoc_audit"
on_the_loop:
examples:
- "create pull request"
- "run database migration in staging"
controls:
- "evaluator_guardrails"
- "rate_limits"
- "anomaly_detection"
in_the_loop:
examples:
- "deploy to production"
- "change auth settings"
- "approve financial transaction"
controls:
- "mandatory_human_approval"
- "two_person_rule"
- "full_audit_trail"Confidence-based routing (with calibration)
Many systems use a confidence threshold to decide escalation.
The key detail: raw model confidence can be misleading. Mature teams calibrate or validate confidence signals using evaluation data, rather than trusting the model’s self-assessment.
Asynchronous authorization
When approval is needed, don’t block the entire system. Use async approvals:
- send an approval request
- let the agent continue other low-risk work
- resume the gated action when approval arrives
Circuit breakers and state machines
A good MAS includes hard stops:
- Finite state machines prevent skipping mandatory steps (e.g., security review before release)
- Circuit breakers stop execution when anomalies appear (unexpected tool usage, call spikes, repeated failures)
This turns “AI behavior” into something you can govern.
Reference architecture: a “silicon workforce” you can ship
Here’s a blueprint that maps well to real enterprise deployment.
Core components
- Orchestrator (Manager/Router)
- Specialist workers
- Evaluator layer (quality gates)
- State + memory
- Governance layer
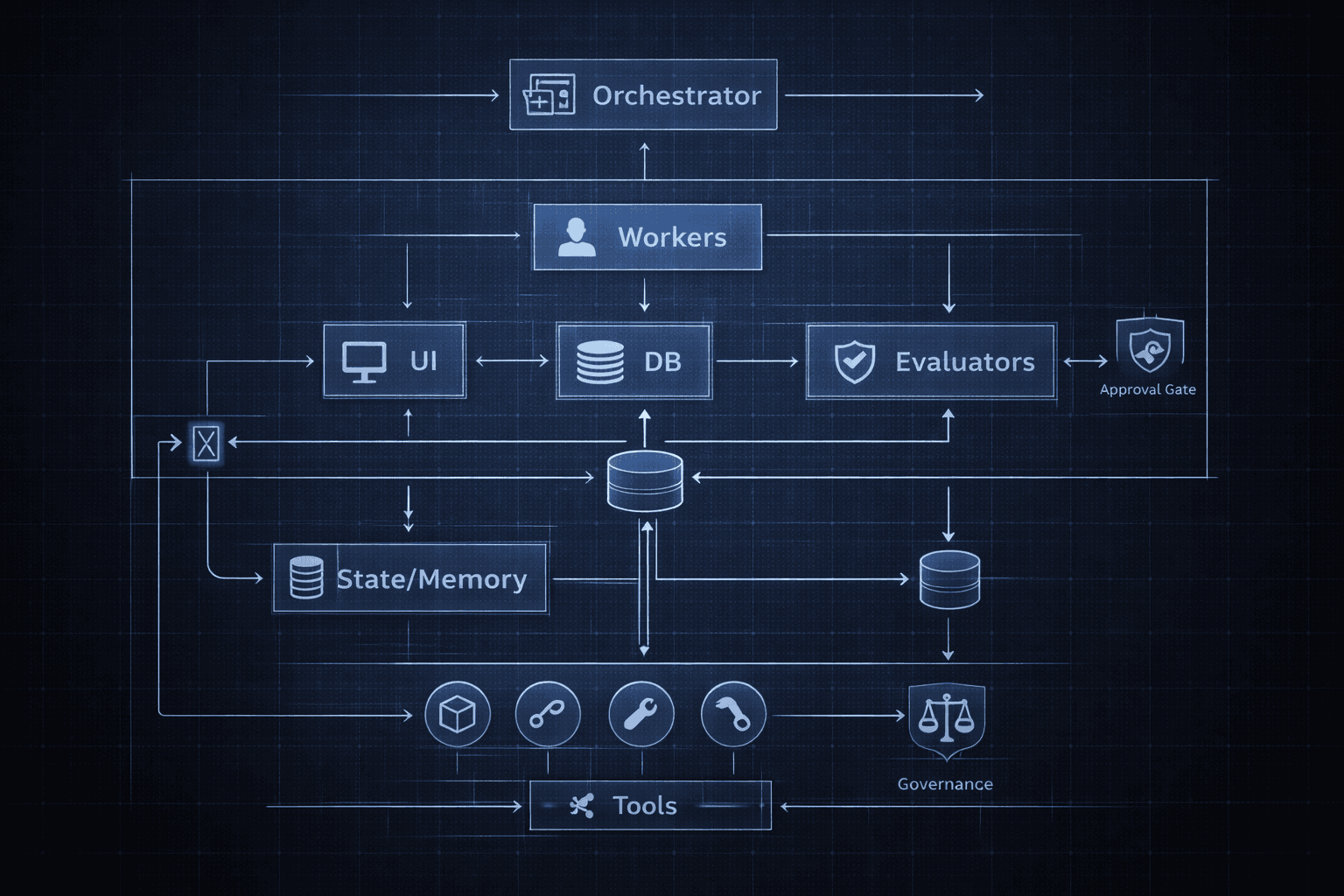
A realistic orchestrator loop (pseudo-code)
# High-level orchestrator loop (pseudo-code)
objective = get_user_objective()
state = init_state(objective)
while not state.done:
tasks = orchestrator.plan(state)
results = run_in_parallel([worker.run(t) for t in tasks])
gated = []
for r in results:
verdict = evaluator.check(r, state)
if verdict.status == "fail":
orchestrator.route_revision(r, verdict)
elif verdict.status == "escalate":
gated.append((r, verdict))
else:
state = merge(state, r)
if gated:
state = request_human_approval(state, gated)
state = orchestrator.summarize_and_checkpoint(state)
return orchestrator.synthesize(state)A worker contract that prevents chaos
Workers should return structured outputs, not paragraphs.
{
"agent": "security_auditor",
"artifacts": {
"findings": [
{"severity": "high", "issue": "Missing CSRF protection", "recommendation": "Add CSRF tokens"}
],
"checklist": ["Password hashing", "Rate limiting", "Session handling"]
},
"confidence": 0.82,
"needs_escalation": true
}This makes evaluation and synthesis much more reliable.
Implementation checklist
If you want to build a production-ready multi-agent system in 2026, prioritize this order:
1) Start with workflow, not models
- Identify the business objective
- Map required subtasks and roles
- Decide what must be deterministic vs exploratory
2) Design state as a product
- Define a shared state schema
- Store artifacts separately from chat history
- Summarize aggressively during handoffs
3) Add evaluators early
- Validate intermediate outputs
- Enforce policy and formatting
- Gate risky steps before they propagate
4) Instrument everything
- log per-agent messages
- trace tool calls
- checkpoint state
- make runs replayable
5) Encode governance-as-code
- define risk tiers
- require approvals where needed
- implement circuit breakers
6) Measure outcomes
- time-to-completion
- escalation rate
- defect rate (bugs/security findings)
- cost per successful run
FAQ
What is a multi-agent system (MAS) in AI?
A multi-agent system is a coordinated group of AI agents that collaborate toward a shared goal—typically with a manager/orchestrator that decomposes tasks, assigns workers, validates outputs, and synthesizes results.
Why is 2026 the “year of multi-agent systems”?
Because enterprises have moved beyond pilots. They need reliable, governed systems that deliver measurable value across complex workflows—something single-agent chatbots struggle to do consistently.
What’s the difference between orchestration and prompt engineering?
Prompt engineering optimizes a single interaction. Orchestration designs a system: routing, state, tools, validation, retries, escalation, and observability.
How do I prevent agents from hallucinating and derailing the workflow?
You don’t rely on trust. You add evaluator guardrails, structured outputs, deterministic baselines for testing, checkpointing, and circuit breakers for anomalies.
Do multi-agent systems always cost more?
Not necessarily. They can reduce cost by using smaller models for narrow tasks, limiting context, parallelizing work, and avoiding expensive failures and rework.
Conclusion
The big story of 2026 isn’t that chatbots got smarter. It’s that AI became a coordinated workforce—specialized agents that can collaborate, validate each other, and operate safely inside governance constraints.
If you want AI that survives production, the winning move is clear:
- Stop treating AI as a single assistant.
- Start building orchestrated systems with roles, handoffs, evaluators, and circuit breakers.
That’s how you move beyond chatbots—and why 2026 is the year of multi-agent systems.
